
Your CI Pipeline Is Too Slow. Which Tests Should Run First?


Modern software systems evolve continuously. Every day, developers submit new code, fix bugs, add features, and refactor existing components. Continuous Integration (CI) pipelines help ensure that these changes do not break the system by automatically running thousands of tests before code reaches production.
But there is a problem: as software grows, so do its test suites.
For many large projects, running the entire test suite for every commit is no longer practical. Some test suites take hours to complete, delaying feedback to developers and increasing infrastructure costs. The result is a tension familiar to many engineering teams: how can we maintain confidence in software quality without slowing down development?
This challenge is not limited to a few organizations. It has become a widespread engineering problem.
At Meta, engineers reported that the sheer number of tests and code changes made it infeasible to execute all potentially impacted tests for every change. Their solution relied on predictive test selection techniques to reduce testing costs while preserving effectiveness [1]. Similarly, Uber has described how large-scale monorepos and frequent code changes can create significant CI bottlenecks, forcing engineers to optimize validation workflows to keep feedback cycles manageable [2].
If you cannot run every test immediately, which tests should you run first?
The Limits of Current Approaches
Over the years, practitioners and researchers have proposed several strategies for selecting and prioritizing tests.
Some approaches rely on simple heuristics:
Run tests that failed recently.
Run tests that historically fail more often.
Run the fastest tests first.
These approaches are attractive because they are easy to implement and require little computational overhead. In fact, recent studies have shown that such simple heuristics often perform surprisingly well in real CI environments.
At the other end of the spectrum are machine-learning-based approaches. These techniques learn from historical build and test data to predict which tests are most likely to reveal failures.
While promising, these solutions come with their own challenges:
Training and maintaining models requires additional infrastructure.
Models must be retrained as projects evolve.
Predictions can become less accurate when development patterns change.
The complexity of the solution may outweigh its benefits in many organizations.
This raises an interesting question:
Can we obtain the benefits of data-driven decision making without the complexity of machine learning?
Introducing DANTE
Commit arrives
↓
1000 tests available
↓
Run all tests? 6 hours
↓
DANTE prioritizes tests
↓
Run top 10% first
↓
Failures detected in minutesTo explore this question, we developed DANTE (Data-Driven Test Case Selection and Prioritization) [3].
DANTE is designed specifically for large CI/CD environments where test suites can take several hours to execute. Rather than relying on fixed heuristics or trained machine-learning models, DANTE continuously learns from information that is already available in most CI pipelines:
Historical test outcomes
Test execution times
Current code changes
The key idea is simple: not all past failures are equally informative.
Learning from Failure Persistence
Many prioritization techniques assume that a test that failed recently is likely to fail again. While this intuition is often correct, reality is more nuanced.
Some failures disappear immediately after a bug fix. Others persist across multiple builds. Some failures are caused by flaky tests and appear only sporadically.
DANTE introduces the concept of failure stickiness.
Instead of simply counting failures, DANTE measures how persistent failures are over time. Tests associated with recurring failures receive higher priority, while isolated or unstable failures contribute less to the decision process.
This allows DANTE to adapt automatically to the characteristics of each project without requiring manually tuned thresholds or retrained models.
Staying Aware of Current Changes
Historical information alone is not enough.
A test that frequently failed in the past may have little relevance to the code currently being modified.
To address this issue, DANTE also analyzes the relationship between the files modified in the current commit and the available test artifacts. By leveraging lightweight information retrieval techniques, it identifies tests that are most closely related to the latest changes.
The result is a prioritization strategy that combines:
What has happened in the past
What is changing right now
without requiring code coverage instrumentation, expensive static analysis, or machine-learning pipelines.
Does It Work?
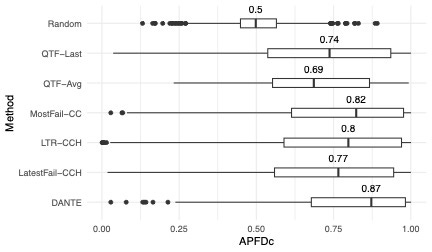
We evaluated DANTE using the Long-Running Test Suite (LRTS) dataset, one of the largest publicly available collections of CI execution data.
The evaluation included:
More than 21,000 CI builds
Nine large-scale open-source projects
Test suites ranging from hundreds to thousands of test classes
Pipelines whose full execution time can reach several hours
The results were encouraging.
Across multiple projects and evaluation scenarios, DANTE consistently:
Detected failures earlier than state-of-the-art heuristic approaches (see the box plot in the figure, higher is better).
Improved test selection effectiveness under constrained time budgets.
Matched or exceeded the performance of machine-learning-based solutions.
Demonstrated strong robustness to flaky tests.
Perhaps most importantly, it achieved these results while remaining lightweight and training-free.
For engineering teams, this means that improved test prioritization does not necessarily require introducing another machine-learning system into the delivery pipeline.
Why This Matters
Fast feedback is one of the fundamental principles of modern software engineering.
When CI pipelines become slower, developers wait longer for validation results, context switching increases, and delivery velocity suffers. At the same time, infrastructure costs continue to grow as organizations execute increasingly large test suites.
The results obtained with DANTE suggest that there is still significant room for improvement between simple heuristics and complex machine-learning solutions.
By combining historical execution data with awareness of current code changes, it is possible to make smarter testing decisions while keeping operational complexity low.
Try It Yourself
DANTE is currently available as a research prototype and replication package [4].
The replication package includes:
The implementation of the approach
Experimental scripts
Evaluation results
Supporting analyses
The current version should be considered a proof of concept rather than a production-ready tool. However, it demonstrates that lightweight, adaptive, and data-driven test prioritization can be highly effective in realistic CI/CD environments.
We are currently working on transforming these research results into a more robust tool that practitioners will be able to evaluate and adopt more easily.
If your CI pipeline is becoming a bottleneck, perhaps the next question is not whether you should run fewer tests.
It is whether you are running the right tests first.
Bibliography
[1] M. Machalica, A. Samylkin, M. Porth and S. Chandra, “Predictive Test Selection,” 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), Montreal, QC, Canada, 2019, pp. 91-100, doi: 10.1109/ICSE-SEIP.2019.00018.
[2] D. Juloori, Z. Lin, M. Williams, E. Shin and S. Mahajan, "CI at Scale: Lean, Green, and Fast," 2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), Ottawa, ON, Canada, 2025, pp. 437-447, doi: 10.1109/ICSE-SEIP66354.2025.00044.
[3] S. Reale, E. Di Nitto, L. Baresi, M. Di Penta, G. Quattrocchi, “DANTE: Data-Driven Test Case Selection and Prioritization for Long-Running Test Suites”, IEEE International Conference on Software Testing, Verification and Validation (ICST) 2026 (available also here https://re.public.polimi.it/handle/11311/1309638).
[4] Reale, S., Di Nitto, E., Baresi, L., Di Penta, M., & Quattrocchi, G. (2026). DANTE: Data-Driven Test Case Selection and Prioritization for Long-Running Test Suites. Replication package. Zenodo. https://doi.org/10.5281/zenodo.18900675